نحوه استخراج جداول از اسناد PDF
این مقاله به شما نشان می دهد که چگونه جداول را از اسناد PDF استخراج(extract tables from PDF documents) کنید. ممکن است فایل های PDF زیادی داشته باشید که حاوی چندین جدول هستند که بخواهید به طور جداگانه از آنها استفاده کنید. کپی(Copying) و چسباندن آن جداول گزینه خوبی نیست زیرا ممکن است خروجی مورد انتظار را ارائه ندهد، بنابراین به گزینه های ساده دیگری نیاز دارید که می توانند جداول را از یک فایل PDF استخراج کرده و آن جداول را به عنوان فایل های جداگانه ذخیره کنند.
اگر جدول PDF(PDF) اسکن شود، اکثر این ابزارهای استخراج جدول PDF(PDF table extractor tools) نمی توانند کمک کنند . در چنین حالتی، ابتدا باید PDF را قابل جستجو(make the PDF searchable) کنید و سپس این گزینه ها را امتحان کنید.
جداول را از اسناد PDF استخراج کنید
در این پست 2 سرویس آنلاین رایگان و 3 نرم افزار رایگان برای استخراج جداول از یک فایل PDF اضافه کرده ایم :
- PDF به XLS
- PDFtoExcel.com
- جدول
- ByteScout PDF Multitool
- Sejda PDF Desktop.
1] PDF به XLS
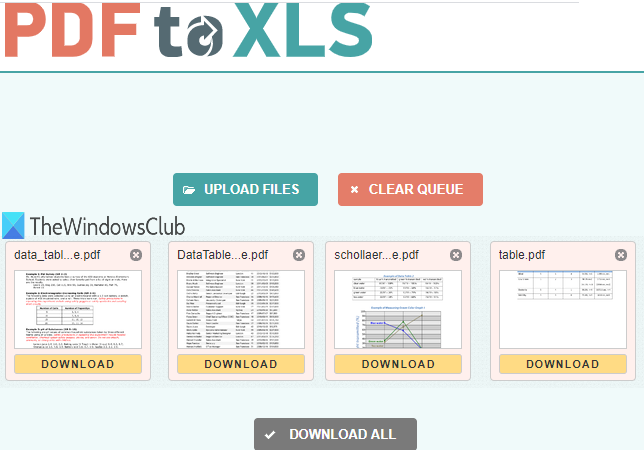
PDF to XLS یکی از بهترین گزینه ها برای استخراج جداول از PDF است. دو ویژگی دارد که آن را خوش دست می کند. می توانید جداول 20(20 PDF) سند PDF را با هم واکشی کنید. همچنین استخراج جدول PDF به صورت خودکار انجام می شود. (PDF)این خروجی را به عنوان یک فایل XLSX تولید می کند. (XLSX)اگر یک PDF دارای چندین جدول باشد، هر جدول به طور جداگانه در برگه های مختلف فایل خروجی XLSX ذخیره می شود.
صفحه اصلی(Open the homepage) این سرویس را باز کنید. پس از آن، فایل های PDF(PDF) را بکشید و یا از دکمه UPLOAD FILES استفاده کنید. هر PDF آپلود شده به صورت خودکار به فایل با فرمت XLSX تبدیل می شود. هنگامی که فایل های خروجی آماده شدند، می توانید آنها را یکی یکی دانلود کنید یا یک فایل ZIP که شامل تمام فایل های خروجی است را دانلود کنید.
2] PDFtoExcel.com

سرویس PDFtoExcel.com(PDFtoExcel.com) می تواند جداول را همزمان از یک PDF استخراج کند اما از چندین پلتفرم برای آپلود PDF پشتیبانی می کند . برای آپلود PDF از پلتفرم های (PDF)OneDrive ، دسکتاپ(desktop) ، Google Drive و Dropbox پشتیبانی می کند . همچنین، فرآیند تبدیل به صورت خودکار است.
این صفحه اصلی سرویس اینجاست(here) . در آنجا، یک گزینه آپلود را برای افزودن PDF انتخاب کنید . پس از آن، به طور خودکار فایل PDF(PDF) را به اکسل(Excel) ( XLSX ) آپلود و تبدیل می کند. هنگامی که خروجی آماده شد، لینک دانلود برای ذخیره فایل خروجی حاوی جدول(های PDF ) را دریافت خواهید کرد.(PDF)
توجه:(Note: ) اگرچه این سرویس اشاره می کند که می تواند جداول را از فایل های PDF اسکن شده نیز استخراج کند، اما برای من کار نکرد. همچنان می توانید آن را برای PDF اسکن شده امتحان کنید .
3] جدول

Tabula یک نرم افزار قدرتمند است که می تواند به طور خودکار جداول موجود در یک PDF را شناسایی کند و سپس به شما امکان می دهد آن جداول را به عنوان فایل TSV ، JSON یا CSV ذخیره کنید. میتوانید گزینه ذخیره فایلهای CSV جداگانه برای هر جدول PDF یا ذخیره همه جداول در یک فایل CSV را انتخاب کنید.
برای دانلود این استخراج کننده جدول PDF منبع باز ، (open-source)اینجا را کلیک کنید(click here) . همچنین برای اجرا و استفاده از آن با موفقیت به جاوا نیاز دارد .(requires Java)
فایل ZIP که دانلود کرده اید را استخراج کنید و فایل Tabula.exe را اجرا کنید. صفحه ای را در مرورگر پیش فرض شما باز می کند. اگر صفحه باز نشد، http://localhost:8080 را در مرورگر خود اضافه کنید و Enter را فشار دهید .
اکنون رابط آن را می بینید که در آن می توانید از گزینه Browse برای افزودن PDF استفاده کنید. پس از آن، دکمه واردات(Import) را فشار دهید. هنگامی که PDF اضافه می شود، می توانید صفحات PDF را در رابط آن مشاهده کنید.
از دکمه تشخیص خودکار جداول(Autodetect Tables) استفاده کنید و تمام جداول موجود در آن PDF را به طور خودکار برجسته می کند. همچنین می توانید به صورت دستی یک جدول را با انتخاب یک جدول خاص برجسته کنید. در صورت تمایل، می توانید جداول(remove selected tables) انتخابی مورد نظر خود را نیز حذف کنید.
این به شما کمک می کند تنها جداول مورد نظر خود را ذخیره کنید. هنگامی که جداول PDF برجسته می شوند، روی دکمه Preview & Export Extracted Data کلیک کنید.
در نهایت، از منوی کشویی موجود در قسمت بالایی برای انتخاب فرمت خروجی استفاده کنید و دکمه Export را فشار دهید. با این کار جداول PDF در فایل فرمت خروجی انتخاب شده توسط شما ذخیره می شود.
4] ByteScout PDF Multitool
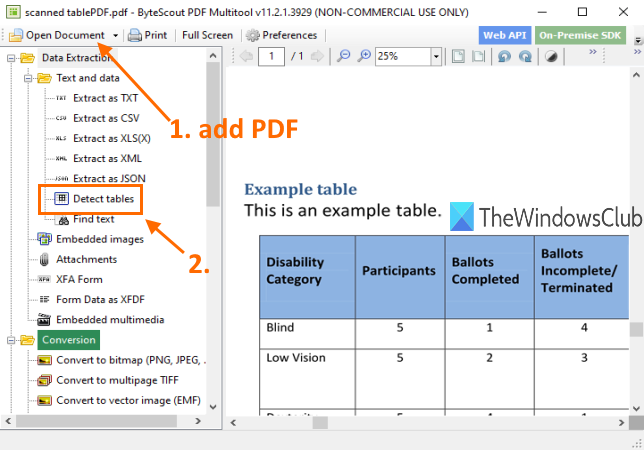
همانطور که از نام آن پیداست، این نرم افزار دارای چندین ابزار می باشد. دارای ابزارهایی مانند تبدیل PDF به TIFF چند صفحه ای(convert PDF to multipage TIFF) ، چرخاندن سند(rotate PDF document) PDF ، غیرقابل جستجو کردن PDF(make PDF unsearchable) ، بهینه سازی PDF(optimize PDF) ، افزودن تصویر به PDF(add an image to PDF) و موارد دیگر. ویژگی آشکارساز جدول PDF(PDF) نیز وجود دارد که بسیار عالی است. مزیت این ابزار این است که می توانید جداول را از PDF اسکن شده(extract tables from scanned PDF) نیز استخراج کنید. میتوانید جداول را در چندین صفحه شناسایی کنید و سپس آن جداول را بهعنوان فایل با فرمت CSV ، XLS ، XML ، TXT یا JSON استخراج کنید. (JSON)قبل از استخراج، همچنین به شما امکان می دهد محدوده صفحه را تنظیم کنید(page range)برای استخراج جداول فقط از صفحات مشخص شده.
شما می توانید این نرم افزار را از اینجا(here) بگیرید. فقط برای استفاده غیرتجاری رایگان(free for non-commercial use) است . پس از نصب، این نرم افزار را اجرا کرده و از گزینه Open Document برای افزودن PDF استفاده کنید. پس از آن، همانطور که در تصویر بالا مشخص شده است ، بر روی ابزار Detect tables کلیک کنید. (Detect tables)این ابزار در دسته استخراج داده ها وجود دارد.(Data Extraction)
کادری را باز می کند که در آن می توانید شرایطی را برای شناسایی جداول تنظیم کنید. به عنوان مثال، میتوانید حداقل تعداد ستونها، ردیفها، حداقل شکست خط بین جداول را تنظیم کنید، حالت تشخیص جدول را روی جدول حاشیهدار یا بدون حاشیه و غیره تنظیم کنید. از گزینهها استفاده کنید یا تنظیمات پیشفرض را حفظ کنید.
پس از آن، دکمه Detect next table را در آن کادر فشار دهید. جدولی را در صفحه فعلی شناسایی و انتخاب می کند. به این ترتیب می توانید به صفحه دیگری بروید و جداول بیشتری را شناسایی کنید.
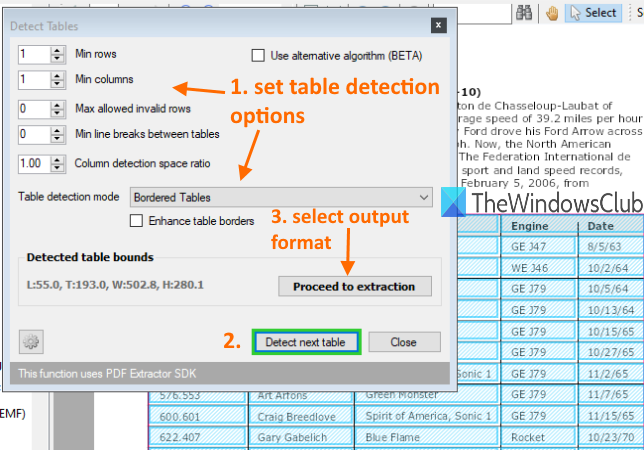
وقتی کارتان تمام شد، از دکمه Proceed to Extract(Proceed to extraction) استفاده کنید و فرمت خروجی را انتخاب کنید. در نهایت، می توانید از گزینه هایی برای ذخیره جداول از صفحه فعلی یا تعریف محدوده صفحه استفاده کنید و خروجی را ذخیره کنید.
ابزار خروجی رضایت بخشی می دهد. اما گاهی اوقات، ممکن است محتوای دیگری را در PDF شناسایی کند و نتواند جداول را از چندین صفحه استخراج کند. در این صورت، باید از آن برای واکشی و ذخیره جداول یکی یکی استفاده کنید.
5] Sejda PDF Desktop
Sejda PDF Desktop نیز یک نرم افزار چند منظوره است. میتواند PDF را بهینه یا فشردهسازی(compress PDF) کند، واترمارک را به PDF اضافه کند، محدودیتها را از PDF حذف کند ، سند (remove restrictions from PDF)PDF را ویرایش کند، و غیره. با این حال، طرح رایگان آن محدودیتهایی دارد. در طرح رایگان فقط 3 کار در روز قابل انجام است. همچنین محدودیت حجم PDF 50 مگابایت(50 MB) یا 10 صفحه(10 pages) است.
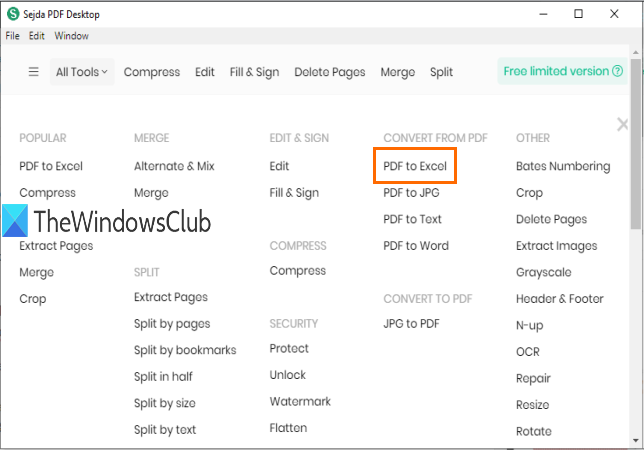
می توانید از ابزار تبدیل PDF به اکسل(PDF to Excel) آن برای استخراج جداول PDF استفاده کنید. (PDF)به طور خودکار جداول را در صفحات PDF شناسایی می کند و به شما امکان می دهد آن جداول را به عنوان XLSX یا CSV ذخیره کنید.
لینک دانلودش اینجاست(here) . پس از نصب، از ابزار PDF به Excel از رابط اصلی آن استفاده کنید. پس از انتخاب آن ابزار، از دکمه Choose PDF files استفاده(Choose PDF files) کنید. فقط یک پی دی اف(PDF) را می توان به طرح رایگان اضافه کرد.
هنگامی که PDF اضافه می شود، دکمه های تبدیل PDF به CSV(Convert PDF to CSV) و تبدیل PDF به اکسل را ارائه می دهد. (Convert PDF to Excel)از یک دکمه استفاده کنید و سپس می توانید خروجی را در مکان مورد نظر در رایانه شخصی خود ذخیره کنید.
ابزار تشخیص جدول PDF آن خوب است. لازم نیست جداول را به صورت دستی شناسایی کنید. با این حال، گاهی اوقات ممکن است محتوای متن دیگری را به عنوان یک جدول PDF شامل شود و آن را در خروجی ذخیره کند. اما نتایج کلی خوب است.
همین.
اینها چند ابزار خوب برای استخراج جداول از PDF هستند. نرم افزار Tabula(Tabula) نسبت به سایر ابزارها موثرتر است. با این حال، می توانید همه ابزارها را امتحان کنید و بررسی کنید که کدام کمک می کند.
مشابه میخواند:(Similar reads:)
- ضمیمه ها را از PDF استخراج کنید(Extract attachments from PDF)
- متن هایلایت شده را از PDF استخراج کنید(Extract highlighted text from PDF) .

About the author
وقتی صحبت از تکنولوژی می شود، هیچ چیز مهمتر از دقت و کیفیت نیست. در مایکروسافت، ما به توانایی خود در ارائه بهترین تجربه ممکن برای مشتریان خود افتخار می کنیم. محصولات ویندوز و iOS ما برخی از نوآورانهترین محصولات در این صنعت هستند و ما دائماً در حال تلاش برای بهبود آنها هستیم. پی دی اف های بدون خطا دلیل دیگری برای موفقیت محصولات ما است. ما می دانیم که کنترل کیفیت در مورد گردش کار و ارتباطات ضروری است، بنابراین ما در حصول اطمینان از اینکه تمام PDF های ما بدون خطا هستند بسیار مراقب هستیم. و در نهایت، به عنوان یک عاشق ابزار، میدانیم که آسانتر کردن زندگی همیشه یک اولویت کلیدی است. ما مطمئن می شویم که همه دستگاه های Lumia ما دارای ویژگی هایی مانند NFC و CarPlay هستند تا بتوانید به راحتی فایل ها را با دوستان و خانواده به اشتراک بگذارید. با این مهارت ها،
Related posts
Document Converter: Convert DOC، PDF، DOCX، RTF، TXT، HTML فایل
PPS file چیست؟ چگونه برای تبدیل PPS به PDF در Windows 11/10؟
PDF text هنگام ویرایش یا ذخیره فایل در Windows 10 ناپدید می شود
Best Free PDF Editor Online Tools که مبتنی بر ابر هستند
PDF Editor Online Tool رایگان برای ویرایش فایل های PDF - PDF Yeah
Compress PDF Software: Compress PDF فایل با استفاده از ابزار PDF Reducer online
چگونه برای تبدیل PDF به MOBI در Windows 10
نحوه تبدیل Text به PDF با Drag and Drop در Windows 10
چگونه به صرفه جویی Email عنوان PDF در Gmail and Outlook
Best Free PDF Stamp Creator software برای Windows 10
7-PDF Website Converter: Convert Web Pages به PDF
چگونه PDF document را به TIFF image چندگانه در Windows تبدیل کنیم
چگونه به ادغام PDF file s متعدد در واحد PDF file
چگونه برای تبدیل اسناد به PDF با CutePDF برای Windows 10
PDF24 Creator PDF Creator رایگان برای ایجاد، تبدیل، ادغام فایل های PDF
دو صفحه View mode را برای PDF در Google Chrome PDF Viewer فعال کنید
LightPDF جامع آنلاین PDF Editor tool برای همه نیازهای PDF شما است
Optimize، فشرده سازی و کاهش PDF File size در Windows 10
نحوه تبدیل Excel file به PDF online با استفاده از Google Drive
Adobe Reader در Windows 10 کار نمی کند